ECL Quarterly Volume V
Tagged as quarterly
Written by Daniel Kochmański on 2016-11-08 15:00
Table of Contents
1 Preface
Dear Readers,
I'm very pleased to present the fifth volume of the ECL Quarterly.
This issue is focused on software development. Tianrui Niu (Lexicall)
written a tutorial on how to embed ECL in Qt5.7. He explains how
to use ECL with C++ software and how to achieve comfortable
development environment for that. Next we have a first part of the
tutorial on creating Common Lisp application from scratch. I hope you
enjoy it. At last some practical opinionated advice about including
all dependencies in the software definitions.
ECL slowly moves towards the next release with a version number
16.1.3. Numerous bugs were fixed, some minor functions were
introduced. We're currently working on simplifying the
autoconf/Makefile files. Configure options were also cleaned. This
may cause some regressions in the build system.
Some code base cleanup was performed with removal of the obsolete code
(which wasn't compiled at all), refactor of testing framework and
making man page up-to-date. One-dash long flags are deprecated in
favour of two-dash alternatives. We've fixed ECL support in upstream
portable CLX and now there is no reason to bundle our own separate
version. Bundled module has been purged. McCLIM works now with the
ECL out of the box.
We've started to implement CDRs (right now CDR1, CDR5, CDR7
and CDR14 are present in ECL with CDR9 and CDR10 on its
way). Constant work on a new documentation is performed.
See the CHANGELOG for more details. I hope to release next version
before the new year.
If you want to discuss some topic with the developers, please join the
channel #ecl on Freenode. If you are interested in supporting
ECL development please report issues, contribute new code, write
documentation or just hang around with us on IRC. Writing about ECL
also increases its mind-share – please do so! Preferably in ECL
Quarterly. If you want to support us financially (either ECL and
ECL Quarterly), please consider contributing on Bountysource.
Enjoy! And don't forget to leave the feedback at daniel@turtleware.eu.
–
Daniel Kochmański ;; aka jackdaniel | TurtleWare
Przemyśl, Poland
November 2016
2 Embedding ECL in Qt5.7
2.1 Introduction
ECL is a fantastic ANSI Commnon Lisp implementation that aims at embedding. It allows us to build Lisp runtime into C/C++ code as external library. That means you can both call C code from Lisp runtime and call Lisp code form the C/C++ part. In this article we focus on how to call Lisp procedures from the C/C++ side, you may also achieve the reversed process by inlining C/C++ code in ECL, but that's beyond our discussion here. Generally, this one-side work is fairly enough to enable us to exhaust any power of both Lisp and C/C++.
This article shows how you can embed ECL into a Qt project, and serve as the kernel of that program. I hope that can serve as a common example, or tutorial, for the one who want to know about the true power of ECL, and perhaps that awesome guy is you. At least we will show you that the ability to hybrid is what makes ECL different from other implementations. And if one day you need that power, you know where you gonna head for.
2.2 But why?
I know I should shoot the code and demo quickly, but let the theory come first, just for those who don't understand why we are doing this.
What we are doing is just an instance of mixed-language programming. That means you will be writing codes in different languages and glue them together to combine a program. Usually, the product program would appear to be a peanut, the kernel is written in language A and the nutshell written in language B. The most frequent combination is C++ and Lua, in game programming. This enables us to take advantage of both language A and B. But in this case we are hybridizing C++ and Common Lisp, both aiming at building large software system, an we are sure to gain even more benifits here.
Common Lisp is a masterpiece, but it lacks a good GUI toolkit. Well, if you work on Linux you definitely can take a shot on packages like CL-GTK or CommonQt, and someone will suggest you to use another package called EQL, the Qt4 binding for ECL. But any of these GUI tools look coarse on my Mac, with Retina screen. I don't want to spend my scholarships on Lispworks, so I must find another way to enable Lisp in GUI-related programming. Finally I ended up in here. The hybrid is no compromise, since I can develop fancy GUI interface without losing the power of Lisp.
We can see more benifits that are shown below:
- Live hotpatching. Common Lisp is a dynamic language, so it allows you to add new components at runtime. That means you can upgrade your program without re-compiling or even restart. In more advanced discussions, you may even recompile your C/C++ functions. So embedded ECL could even change the host language.
- With the most powerful macro system, Lisp is natively designed for complex system designing. Different from light-weight languages like Python and Lua, Lisp is suitable for huge programs. So you can always focus on Lisp, instead of seeking for help from language B. You can also use Lisp environment as a direct DSL interpreter so that you needn't write one yourself.
- Efficiency. There are other approaches to combine Lisp runtime with other languages, like using pipes, channels, sockets or temporary files. These are never elegant solutions, since you can only read the output by Lisp runtime manually and there's no direct access to the Lisp runtime memory. And you have to string-parse each Lisp output. So this is neither quick nor efficient. You may also use FFIs (Foreign Language Interfaces) and it's more common with the reverse direction, say call C from Lisp. Now the ECL approach is to save. The Lisp runtime in ECL shares the same part of memory with C/C++ side and there's direct way to fetch the return value of any Lisp function calls. How can they achieve this magic? Well ECL compiles Lisp to C code or bytecode so that they get the same tone.
- Stable and mature. ECL is currently the best for embedding. You may have heard of other implementations like Clasp, which works on LLVM and is compatible with C++. But it's not yet stable or ANSI-compatible hitherto. Meanwhile ECL has a long history and is already ready to use. When built with C++ compiler like g++ (flag –with-cxx), ECL also enables us to Call C++ functions. So stick to ECL.
I hope this should convince you that this could be a promising hybrid.
2.3 General Approach
The embedding process of ECL can be pretty simple if you understand how it works. Unfortunately the ECL official documentation of this part is not quite clear at the moment, here are some example code in the example/embed directory. Thanks to Daniel Kochmański, he helped me through the way towards my first success of hybridding. I'm still a newbie here.
The example code is enough for understanding the process of hybridizing Lisp and C codes by ECL. There is absolutely a general approach and you can use it as a pattern in your development.
ECL achieves this by compiling itself into C libraries and link it to C runtime. There is two ways to go: static library and shared library. In this article we will take the first approach. For embedding, there are a few steps:
- Write your Lisp files. (absolutely)
- Compile your Lisp files.
- Write a C/C++ file that includes the ECL library and boots the CL environment.
- Link the runtime and compile the whole project into executables.
Easy enough, isn't it? Let me explain in detail.
The first step is nothing different than general Lisp development. You can either create your own package or not. (Just leave the naked lisp file.)
The second step, well, it's time for ECL to rock. We've got two
approaches, which depend on whenever you use ASDF or not. If you do
not want to use it, you may follow this code:
(compile-file "<YOUR-LISP-FILE>.lisp" :system-p t)
(c:build-static-library "<LIBRARY-NAME>"
:lisp-files '("<THE-OBJECT-FILE>.o")
:init-name "<INIT-NAME>")
The first line of code compiles your .lisp file into a .o object file, say, <THE-OBJECT-FILE>.o. This file serves as the input for the next procedure. The c:build-static-library function is defined by ECL, it builds the object file into a static library, say, <LIBRARY-NAME>.a. We should pay attention to the init-name. You can define your init-name here as a string, and this is useful for step 3. We will head back when it happens.
If you choose to use ASDF, you can head for the asdf:make-build
function. This can be seen in the Makefile in example:
hello.exe: hello.c hello-lisp.a
$(CC) `ecl-config --cflags` -o $@ hello.c hello-lisp.a \
`ecl-config --ldflags` -lecl
hello-lisp.a: hello-lisp.lisp
ecl -norc \
-eval '(require :asdf)' \
-eval '(push "./" asdf:*central-registry*)' \
-eval '(asdf:make-build :hello-lisp :type :static-library :move-here "./")' \
-eval '(quit)'
clean:
-rm -f hello-lisp.a hello.exe
And you may use asdf:defsystem in your lisp code. We will see this
closer in my demo.
In the third step, we must dance with some C/C++ code. In
your .c file where you want the ECL environment to run,
you should #include <ecl/ecl.h> to make sure all the ECL symbols
are linked. Then write some simple code to boot the environment:
/* Initialize ECL */ cl_boot(argc, argv); /* Initialize the library we linked in. Each library * has to be initialized. It is best if all libraries * are joined using ASDF:MAKE-BUILD. */ extern void init_lib_HELLO_LISP(cl_object); ecl_init_module(NULL, init_lib_HELLO_LISP);
The cl_ boot procedure boots the CL environment, it takes the right
args from your main entry. Now take a look at the extern
declaration. Remember last time I suggest you to notice the
:init-name, now it's time to use it. If you took the first approach
of building library and defined your own *init-name*, now the function
name should be the same with it. And if you didn't define your
init-name, now the name convention should be:
init_lib_<FILE_NAME_OF_THE_LIBRARY>. Say, if the static library
named "hello-world–all-systems.a", then you write
init_lib_HELLO_WORLD__ALL_SYSTEMS for the function name.
Notice: In C++, you should encapsule the extern code in an extern "C" block:
extern "C"{
extern void init_lib_HELLO_LISP(cl_object);
}
To make the link process complete. This has something to do with the
naming convention that differs from C to C++. In general ECL exports
symbols following C naming convention to allow seamless FFI to it from
C and other languages. C++ does some weird name mangling.So if you want
to call C functions from C++, you have to declare them in C++ that way indeed.
The function is used by procedure ecl_init_module to load all of
your user-defined Lisp symbols. Then you are freely to call your Lisp
code in C/C++.
The forth step builds the whole project. So it acquires all of your C/C++ files, libraries and the ECL library. All of the work can be easily done if you are familiar with Makefile. See the example above.
2.4 Calling Lisp in C/C++
"How can I call the Lisp functions I wrote?" This should be the most
urgent question you may ask. The ECL manual describes most of the
functions in the Standards chapter. Apparently most of the Lisp
functions, or macros have been maped into C functions, with some name
convention. For example the [[https://common-lisp.net/project/ecl/static/manual/re02.html][cl_ eval]] means the corresponding Lisp
code "eval". Most of the ANSI-defined procedure has the naming
convention of using cl_ as prefix. So you can easily find the
primitive symbol you need.
But perhaps the problem you most concern is:
- How can I call MY Lisp functions in C/C++?
- How can I translate the return value into C/C++ objects?
For the first question I suggest you to use the cl_eval
function. The reason is it's simple and extensible. For the safety
reasons you may use cl_funcall or cl_safe_eval. But none of them
is as universal as cl_eval. The cl_funcall, as its name means, can
only call functions and cannot be used to call macros. And
cl_safe_eval requires more parameters in order to handle potential
errors that may occur on the Lisp side. But here since I don't mean to
make my code productive so I won't care about the safety or convenience.
I wrote a friendlier version of cl_eval and you can call lisp code like
this:
cl_eval("mapcar", list_foo, "(lambda (x) (princ x))");
And that's nearly Lisp code in appearance.
So let's head for the cl_eval. Its signature is:
cl_object cl_eval(cl_object);
It receives a cl_object and returns a cl_object. Hmm. Now you
should get knowledge of how ECL manipulate Common Lisp Objects before
wondering what cl_object is.
Quite simple. ECL encapsules any Lisp object into the same structure
cl_object. It's a C union whose definition can be seen in object.h,
line 1011. So you don't need to worry about using different types to
capture the return value.
Translating C strings to cl_object is trivial: use the
c_string_to_object function:
cl_object c_string_to_object (const char * s)
You just write the Lisp form in C string and the function will create Lisp object for you. So you may write
cl_eval(c_string_to_object("(princ \"hello world\")"));
To get your first hybrid-call.
The second question can be a little tough due to lack of documentation. And there's another naming convention.
Generally, you may use the ecl_to_* family to convert the
cl_object to primitive C data, here is some regular examples:
char ecl_to_char(cl_object x); int ecl_to_int(cl_object x); double ecl_to_double(cl_object x);
I've said that these functions could only help convert cl_object to
primitive C data. No array, and no string. The ECL API didn't provide
them officially. So we have to implement them manually, sorry to say
that. (If I missed something, correct me.)
I would show two trivial yet useful functions that may help you. The first one helps you to traverse Lisp List:
auto cl_list_traverse=[](auto& cl_lst, auto fn){
while(!Null(cl_lst))
{
fn(cl_car(cl_lst));
cl_lst=cl_cdr(cl_lst);
}
};
This is implemented in C++ with the convenience of C++14 standard. Can be rewritten in C like this:
void cl_list_traverse(cl_object cl_lst, void(*fn)(cl_object)){
while(!Null(cl_lst))
{
fn(cl_car(cl_lst));
cl_lst=cl_cdr(cl_lst);
}
};
Usage example:
void print_element(cl_object obj){
printf("%d\n", ecl_to_int(obj));
}
list_traverse(foo_list, print_element);
And the second one converts the cl_object into C++ *std::string*.
std::string to_std_string(cl_object obj){
std::string val;
auto & str=obj->string;
for(unsigned long i=0;i<str.fillp;i+=1)
val+=*(typeof(str.elttype) *)(str.self+i);
return val;
}
When you are using these functions to convert a cl_object
to C/C++ objects, you have to know exactly what the return value
is. That means, if you are trying to call ecl_to_int
on a cl_object, you should be clear that
the cl_object IS an integer. And for some
complicate situation, a cl_object could contain more than
one type at the same time. For example, if you call a function that
returns a list of strings, say '("hello" "lisp") then the
corresponding
cl_object can both contain a string (on its car position) and a list
(on its cdr position). Call cl_car and you get a cl_object
containing a string, and you can call to_std_string on that object
to get a C++ string. I mean, you should figure out that before you
code. The secret is to just think you are still in Lisp.
2.5 Hybridizing Lisp & Qt
Now it's time to head for our ultimate goal: let Lisp rock with Qt! We have had enough knowledge of embedding ECL into C++ code in the former chapters and Qt is nothing but C++. So the work should be trivial. Sounds this is true but, there's still many things to be solved. I have stuggled much about them but now I can just write down the final progress and pretend this is simple.
The first one is, how to build a Lisp package system, instead of compiling a naked Lisp file or a single package.
2.5.1 Build Lisp Package System
If you are to build some awesome software, you must be using external
packages. After all, there are plenty of excellent Lisp packages, like
cl-ppcre and lparallel. Quicklisp solved the package management
problem in an elegant way. But when you decide to distribute your
software, you shouldn't ask Quicklisp for help, instead, you should
compile all of your dependencies into your Lisp runtime, so that you
can load them all by a single statement. SBCL could dump current Lisp
image into a single executable file by function
sb-ext:save-lisp-and-die. We need a function that does the similar
thing, here in ECL.
ASDF is here to help. You can make an asdf system that defines every files and dependencies in your project. If you haven't touched that, see the tutorial.
After that, you just have one step to go: build the system into library. You may use asdf:make-build. Here comes an example:
(require 'asdf)
(push "./" asdf:*central-registry*)
(asdf:make-build :hello-lisp-system
:type :static-library
:monolithic t
:move-here "./")
The push expression adds current working directory into ASDF
search list. Then asdf is ready to find your user-defined system in
your directory.
If you have external Lisp packages as dependencies, you must set the
:monolithic parameter to T. That means, you order ASDF to build
your whole system into a single file. Or else you'd have to load your
dependencies manually each time you start your Lisp runtime.
Unfortunately, I have to say the function is not ready for building static libraries that contains Lisp package dependencies. There is a serious bug that prevents the library from linking. So the example code shown above won't work!. Sorry to say that. But perhaps this code works fine in the future. :)
Don't be afraid. There is still two other approaches, to build a fasl file or the shared library.
I'll take the first approach since it brings some good advantages. That is, allowing us to distribute the Lisp system independently. You can debug either natively in ECL by loading the fasl file or remotely on the C/C++ side. Sometimes you need this because you don't know which side, say C or Lisp, that causes your program crash.
Since then, I have to build two different Lisp systems. The first one serves as the Lisp runtime and is build to static library. It contains just one line of Lisp code.
(princ "Lisp Environment Settled.")
This library will be linked to my C++ program. The second one will be the actual system I wrote. I'm building it into a independent fasb file.
(require 'asdf)
(push "./" asdf:*central-registry*)
(asdf:make-build :hello-lisp-system
:type :fasl
:monolithic t
:move-here "./")
(quit)
After loading this code I will see a hello-lisp-system–all-systems.fasb file in my directory. In order to use the system, I should load that fasl file at runtime. So the init code should be:
/* init-name */
#define __cl_init_name init_lib_LISP_ENVI
extern "C"{
extern void __cl_init_name(cl_object);
}
void init_cl_env(int argc, char * argv[]){
/* Initialize CL environment */
cl_boot(argc, argv);
ecl_init_module(NULL, __cl_init_name);
/* load fasb */
cl_eval("load", CL_MAIN_FASB);
/* set context to current package */
cl_eval("in-package", CL_MAIN_PACKAGE_NAME);
/* hook for shutting down cl env */
atexit(cl_shutdown);
}
#undef __cl_init_name
There is also a function called cl_load, you may use it to load the bundle:
Signature: cl_object cl_load(cl_arg narg, cl_object path);
Usage: cl_load(1, c_string_to_object("./lisp_image.fasb"));
Notice: When you are using the Lisp runtime, you are in the :top context.
Notice: The cl_eval function I used is the
optimized, or overloaded version which I will introduce in the next
section.(Code
is here.) If you stick to the original version, you should convert
C string to cl_object manually, like:
cl_eval(c_string_to_object("'hello"));
2.5.2 Enhance ECL Bridge In C++14
ECL is written in pure C, as a result, it lacks the real object to
describe Lisp data. The cl_ object structure unions the Lisp datas
together but there is no method for it. Utility functions are
just naked funtions. You have to write ecl_to_int(obj) to
convert the object to int, but it would be friendlier if you can write
that as
obj.to_int(). At this moment we are going to enclosure the original
cl_ object in a C++ object to implement this.
auto cl_list_traverse=[](auto& cl_lst, auto fn){
while(!Null(cl_lst))
{
fn(cl_car(cl_lst));
cl_lst=cl_cdr(cl_lst);
}
};
class cl_obj {
private:
cl_object __obj;
public:
cl_obj(cl_object &&obj){this->__obj=obj;}
cl_obj(const cl_object &obj){this->__obj=obj;}
/* list index */
inline cl_obj car(){return cl_obj(cl_car(this->__obj));}
inline cl_obj cdr(){return cl_obj(cl_cdr(this->__obj));}
inline cl_obj cadr(){return this->cdr().car();}
inline cl_obj caar(){return this->car().car();}
inline cl_obj cddr(){return this->cdr().cdr();}
/* predicates */
inline bool nullp(){return Null(this->__obj);}
inline bool atomp(){return ECL_ATOM(this->__obj);}
inline bool listp(){return ECL_LISTP(this->__obj);}
inline bool symbolp(){return ECL_SYMBOLP(this->__obj);}
inline int to_int(){return ecl_to_int(this->__obj);}
inline char to_char(){return ecl_to_char(this->__obj);}
inline std::string to_std_string(){
std::string val;
auto & str=this->__obj->string;
for(unsigned long i=0;i<str.fillp;i+=1)
val+=*(typeof(str.elttype) *)(str.self+i);
return val;
}
template<typename function>
inline void list_traverse(function fn){cl_list_traverse(this->__obj, fn);}
inline cl_obj operator=(cl_object &&obj){return cl_obj(obj);}
};
It's just a trivial one and can only implement a small subset of ANSI
Common Lisp, but anyway it's enough for our demo. After that, you can
write something like obj.cdr().car().to_ int(). That is a more
fluent interface.
Despite that, the original cl_eval function is not friendly
enough. We are going to implement a better one so that you can call
that function just as if you are in Lisp. See the overloading:
using std::string;
cl_object lispfy(string str);
return c_string_to_object(str.data());
}
string __spc_expr(string first);
template <typename ...str>
string __spc_expr (string first, str ... next){
return first+" "+__spc_expr(next...);
}
template<typename ...str>
string par_expr(str... all){
return "("+__spc_expr(all...)+")";
}
template<typename ...str>
string par_list(str... all){
return "'"+par_expr(all...);
}
template<typename ...str>
string cl_eval(str... all){
return cl_eval(lispfy(par_expr(all...)));
}
Now you can call that cl_eval function like:
cl_eval("mapcar", "'(1 2 3 4 5)", "(lambda (x) (evenp x))");
Those code would compile by setting your compiler to -std=c++14.
2.5.3 Time to Hybridize!
After gaining the knowledge in the former chapter, it's trivial for us to use ECL in Qt programming. You just have to follow some small modifications and tips.
Source code of the demo being shown here can be found here.
First you should get a little knowledge about qmake. It's an automatic
toolchain that helps us build our program. This time we needn't write
Makefile manually since qmake is quite easy to use. You should check
your .pro file and add those code to it:
QMAKE_CFLAGS += `ecl-config --cflags` QMAKE_CXXFLAGS += `ecl-config --cflags` QMAKE_LFLAGS += `ecl-config --ldflags` LIBS += -lecl LIBS += <THE PATH OF YOUR STATIC LIBRARY (LISP RUNTIME)>
ecl-config will generate flags for your compiler.
And since I used C++14, I have to add:
CONFIG+=c++14
And we should also do a small trick. Because Qt defined the macro
slots as keyword, it conflicts with the slots defined in ecl.h. So
we have to undef that keyword to turn off the interference:
#ifdef slots #undef slots #endif #include <ecl/ecl.h>
Now you can check out my demo. It looks like this:
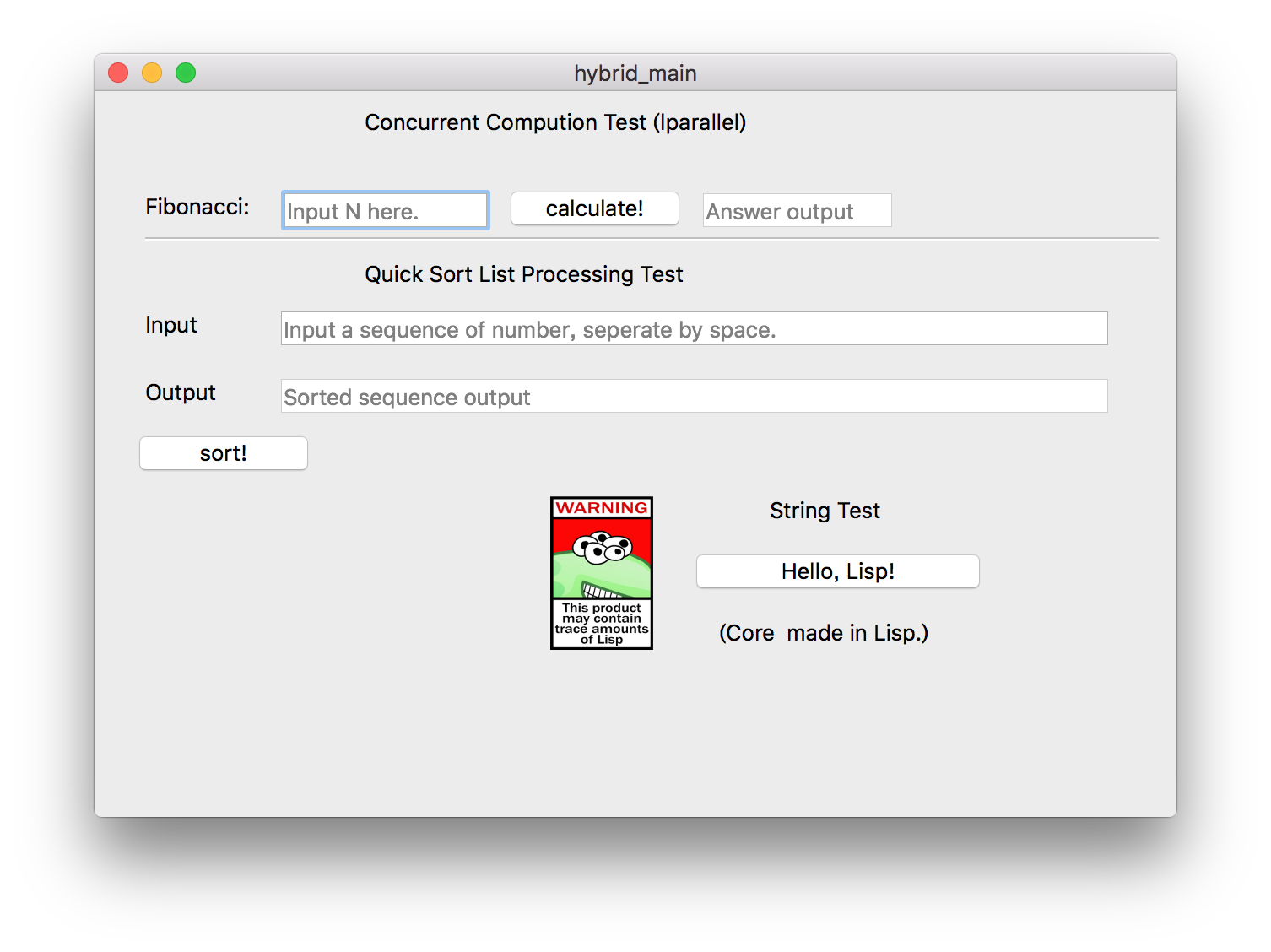
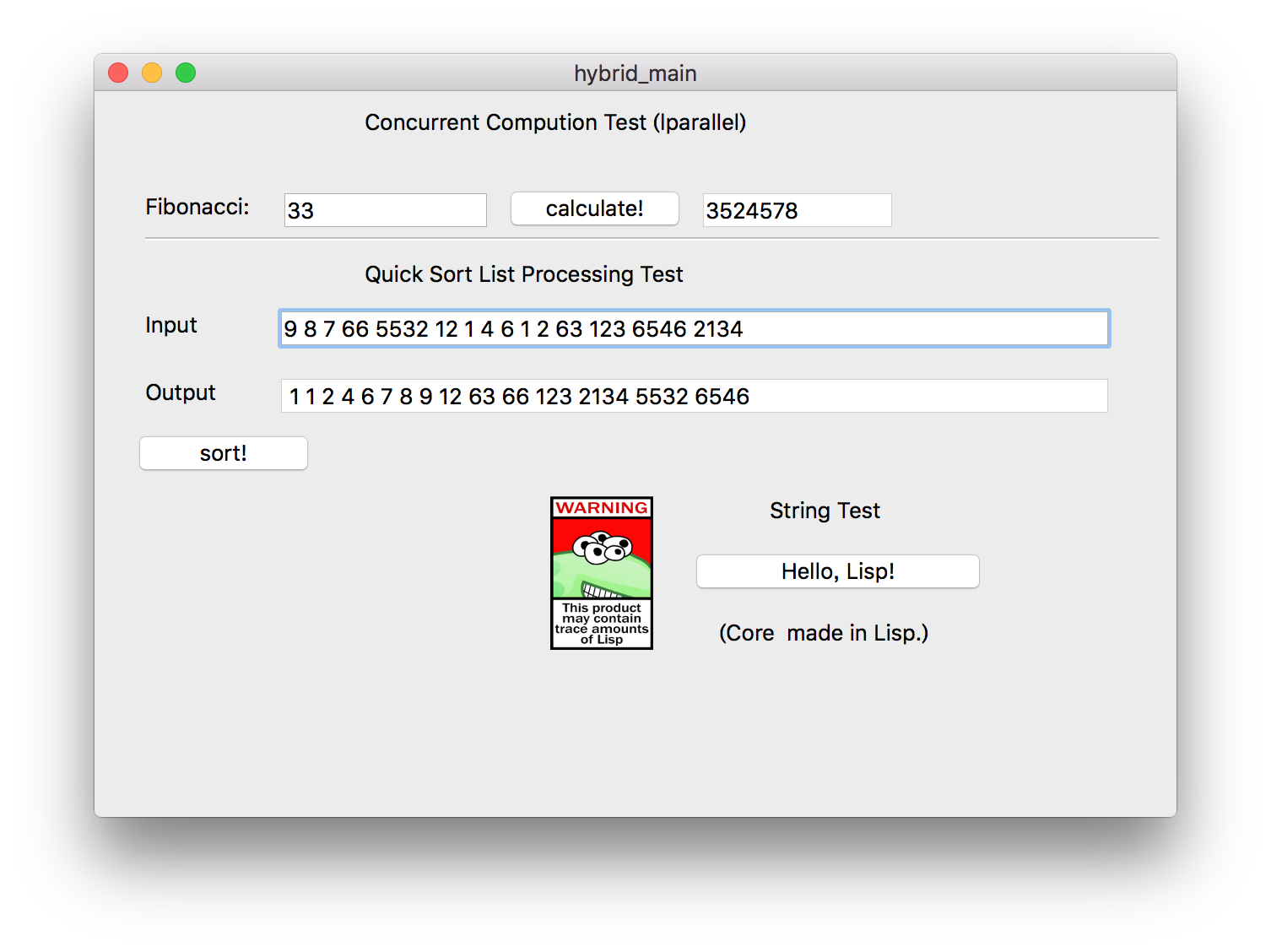
It's just simple but enough to serve as a demo. The Lisp code of Fibonacci demo is based on package lparallel, the concurrent package.
(defpackage :hello-lisp
(:use :cl :lparallel))
(in-package :hello-lisp) ;;package name hello-lisp
(setf lparallel:*kernel* (lparallel:make-kernel 4))
(lparallel:defpun pfib (n)
(if (< n 2)
n
(plet ((a (pfib (- n 1)))
(b (pfib (- n 2))))
(+ a b))))
You see, that's concurrent computation! This function should take use of all my four CPU cores. So that one is to show you how we can use external Lisp packages in our ECL.
The second demo is Quicksort. It just sorts the List you passed and print the result on the output line. This one demostrates the method to load and traverse Lisp list.
Click the hello-lisp button and you get an echo:
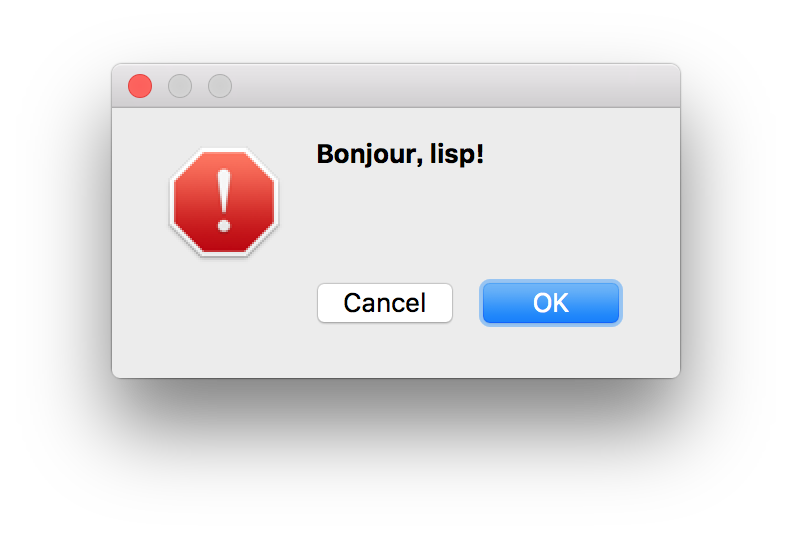
The text "Bonjour, lisp!" is returned by a Lisp function. This
demostrates how to extract strings from cl_object.
Now you are ready for deeper adventure with embedding ECL. Good luck!
Note: For OSX users, after you build the source code by qmake, make, you should also run this shell code:
mv hello-lisp-system--all-systems.fasb ecl_qtdemo.app/Contents/MacOS/
To make sure the Lisp system is right in the place. For Linux users you are not bothered by this since Qt won't make application packages in default.
3 Creating a Common Lisp project – Part I
3.1 Introduction
A common question heard from the Common Lisp newcomers is:
How to create my own application with Common Lisp?
Numerous concepts like packages, Quicklisp, modules and ASDF bring the confusion, which is only deepened by a wide range of implementations and foreign to the new programmer developing paradigm of working on a live image in the memory.
This post is a humble attempt to provide a brief tutorial on creating a small application from scratch. Our goal is to build a tool to manage document collection. Due to the introductory nature of the tutorial we will name our application "Clamber".
We will start with a quick description of what should be installed on
the programmer's system (assumed operating system is Linux). Later we
will create a project boilerplate with the quickproject, define a
protocol for the software, write the application prototype
(ineffective naive implementation), provide the command line interface
with Command Line Option Nuker. This is where the first part ends.
Second part will be published on McCLIM blog and will show how to
create a graphical user interface for our application with McCLIM.
Afterwards (in a third part in next ECL Quarterly) we will take a
look into some considerations on how to distribute the software in
various scenarios:
- Common Lisp developers perspective with
Quicklisp, - ordinary users with system-wide package managers with
ql-to-deb, - source code distribution to clients with
Qucklisp Bundles, - binary distribution (closed source) with
ADSF prebuilt-system, - as a shared library for non-CL applications with
ECL.
Obviously a similar result may be achieved using different building blocks and all choices reflect my personal preference regarding the libraries I use.
3.2 How to distribute the software
Before we jump into the project creation and actual development I want to talk a little about the software distribution. We may divide our target audience in two groups – programmers and end users. Sometimes it is hard to tell the difference.
Programmers want to use our software as part of their own software
as a dependency. This is a common approach in FOSS applications,
where we want to focus on the problem we want to solve, not the
building blocks which are freely available (what kind of freedom it is
depends on the license). To make it easy to acquire such dependencies
the Quicklisp project was born. It is a package manager.
End users aren't much concerned about the underlying technology. They want to use the application in the most convenient way to them. For instance average non-programming Linux user would expect to find the software with theirs system distribution package manager. Commercial client will be interested in source code with all dependencies with whom the application was tested.
Proposed solution is to use Quicklisp during the development and
bundle the dependencies (also with Quicklisp) when the application
is ready. After that operation our source code doesn't depend on the
package manager and we have all the source code available, what
simplifies further distribution.
3.3 What are Common Lisp systems?
Notion of "system" is unknown to the Common Lisp specification. It is
a build-system specific concept. Most widely used build-system in 2016
is ASDF. System definition is meant to contain information essential
for building the software – application name, author, license,
components and dependencies. Unfortunately ADSF doesn't separate
system definitions from the source code and asd format can't be
considered declarative. In effect, we can't load all system
definitions with certainty that unwanted side-effects will follow.
3.4 Development environment configuration
We will only outline steps which are necessary to configure the development environment. There are various tutorials on how to do that which are more descriptive.
Install Emacs and
SBCL1:These two packages should be available in your system package manager (if it has one).
Install
Quicklisp:Visit https://www.quicklisp.org/beta/ and follow the instructions. It contains steps to add
Quicklispto Lisp initialization file and to install and configureSLIME. Follow all these instructions.Start Emacs and run Slime:
To run Slime issue
M-x slimein Emacs window.
These steps are arbitrary. We propose Linux + SBCL +
Emacs + Quicklisp + SLIME setup, but alternative configurations are
possible.
3.5 How to create a project
Quickproject is an excellent solution for this task because it is very simple tool with a well defined goal – to simplify creating basic project structure.
The simplest way of creating a new one is loading the quickproject
system with Quicklisp and calling the appropriate function. Issue
the following in the REPL:
(ql:quickload 'quickproject)
(quickproject:make-project #P"~/quicklisp/local-projects/clamber/"
:depends-on '(#:alexandria)
:author "Daniel Kochmański <daniel@turtleware.eu>"
:license "Public Domain")
That's it. We have created a skeleton for our project. For now, we
depend only on alexandria – public domain utility library. List of
dependencies will grow during the development to reflect our needs. Go
to the clamber directory and examine its contents.
Now we will customize the skeleton. I prefer to have one package per
file, so I will squash package.lisp and clamber.lisp into
one. Moreover, README.txt will be renamed to README.md, because we
will use markdown format for it.
To avoid clobbering the tutorial with unnecessary code we put only interesting parts here. Complete steps are covered in the application GIT repository available here:
https://gitlab.common-lisp.net/dkochmanski/clamber
We propose to clone the repository and track the progress with the subsequent commits and this tutorial.
3.6 Writing the application
Here is our application Clamber informal specification:
- Application will be used to maintain a book collection,
- Each book has associated meta-information (disregarding the underlying book file format),
- Books may be organized with tags and shelves,
- Book may be only on one shelf, but may have multiple tags,
- Both CLI and GUI interfaces are a required,
- Displaying the books is not part of the requirements (we may use external programs for that).
- Protocol
First we will focus on defining a protocol. Protocol is a functional interface to our application. We declare how external modules should interact with it. Thanks to this approach we are not tied to the implementation details (exposing internals like hash tables or class slot names would hinder us during the future refactoring, or could cause changes which are not backward compatible).
;;; Clamber book management protocol ;;; Requirements explicitly list that books has to be organized by ;;; shelves and tags. Book designator is used to identify books (it ;;; has to be unique). Protocol doesn't mandate designator type. It ;;; may be a unique name, pathname, URL or any arbitrary ;;; object. Other args (in form of keys) are meant to contain ;;; meta-information. (defgeneric insert-book (book-designator &rest args &key shelf tags &allow-other-keys) (:documentation "Creates a book entity associated to a given ~ `shelf' and `tags'.")) ;;; We need to bo able to remove book. We need only the designator for ;;; that. (defgeneric delete-book (book-designator) (:documentation "Removes a book entity from the system.")) ;;; We may search for books according to various ;;; criteria. `book-designator' is definite. It is possible to extend ;;; the find functionality to support other criteria. Book must match ;;; *all* supplied criteria. (defgeneric find-books (&rest args &key book-designator shelf tags &allow-other-keys) (:documentation "Returns a `sequence' of books matching the ~ requirements.")) ;;; We access books by their designators, but `find-books' returns a ;;; list of opaque objects. This function is needed for coercion from ;;; these objects to the designators. Sample usage: ;;; ;;; (map 'list #'book-designator (find-books :shelf "criminal")) (defgeneric book-designator (book) (:documentation "Extract book designator from opaque `book' object."))This code is put in
clamber.lispfile. It is important to remember, that:documentationclause indefgenericis meant only for programmers who use our library (to provide a short reminder of what the function does) and shouldn't be considered being the final documentation. Especially docstrings are not documentation.Comments are meant for programmers who work on our library (extend the library or just read the code for amusement). Their meaning is strictly limited to the implementation details which are irrelevant for people who use the software. Keep in mind, that comments are not reference manual.
- Implementation prototype
Our initial implementation will be naive so we can move forward faster. Later we could rewrite it to use a database. During the prototyping programmer may focus on the needed functionality and modify the protocol if needed.
This is a tight loop of gaining the intuition and adjusting rough edges of the protocol. At this phase you mustn't get too attached to the code so you can throw it away without hesitation. More time you spend on coding more attached to the code you are.
;;; Implementation ;;; At start we are going to work on in-memory database. (defparameter *all-books* (make-hash-table) "All defined books.") ;;; Note, that when we define `:reader' for the slot `designator' we ;;; actually implement part of the protocol. (defclass book () ((designator :type symbol :initarg :des :reader book-designator) (shelf :type string :initarg :shl :reader book-shelf) (tags :type sequence :initarg :tgs :reader book-tags) (meta :initarg :meta :accessor book-information))) ;;; `title' and `author' are enlisted for completion. (defmethod insert-book ((designator symbol) &rest args &key shelf tags title author &allow-other-keys &aux (tags (alexandria:ensure-list tags))) (declare (ignore title author readedp) (type (shelf string))) (multiple-value-bind (book found?) (gethash designator *all-books*) (declare (ignore book)) (if found? (error "Book with designator ~s already present." designator) (setf (gethash designator *all-books*) (make-instance 'book :des designator :shl shelf :tgs (coerce tags 'list) :meta args))))) ;;; Trivial (defmethod delete-book ((designator symbol)) (remhash designator *all-books*)) ;;; We use `while-collecting' macro (`collect' equivalent from ;;; cmu-utils) to simplify the code. (defmethod find-books (&rest args &key (book-designator nil designator-supplied-p) (shelf nil shelf-supplied-p) (tags nil tags-supplied-p) &allow-other-keys &aux (tags (alexandria:ensure-list tags))) (declare (ignore args)) (uiop:while-collecting (match) (labels ((match-book (book) (and (or (null shelf-supplied-p) (equalp shelf (book-shelf book))) (or (null tags-supplied-p) (subsetp tags (book-tags book) :test #'equalp)) (match book)))) (if designator-supplied-p (alexandria:when-let ((book (gethash book-designator *all-books*))) (match-book book)) (alexandria:maphash-values (lambda (val) (match-book val)) *all-books*)))))Our prototype support only shelf and tags filters and allows searching with a designator. Note that
book-designatorfunction is implemented in our class definition as a reader, so we don't have to define the method manually. We adduiopto dependencies for thewhile-collectingmacro (descendant of acollectmacro incmu-utils).We may check if our bare (without user interface) implementation works:
(ql:quickload :clamber) ;; -> (:CLAMBER) (clamber:insert-book 'captive-mind :shelf "nonfiction" :tags '("nonfiction" "politics" "psychology") :title "The Captive Mind" :author "Czesław Miłosz") ;; -> #<CLAMBER::BOOK {100469CB73}> (clamber:find-books :tags '("politics")) ;; -> (#<CLAMBER::BOOK {100469CB73}>) - Unit tests
Now we will add some basic unit tests. For that we will use
fiveamtesting framework. For seamless integration withASDFand to not include the tests inclamberitself we will define it as a separate system and point to it with the:in-order-toclause:(asdf:defsystem #:clamber :description "Book collection managament." :author "Daniel Kochmański <daniel@turtleware.eu>" :license "Public Domain" :depends-on (#:alexandria #:uiop) :serial t :components ((:file "clamber")) :in-order-to ((asdf:test-op (asdf:test-op #:clamber/tests)))) (asdf:defsystem #:clamber/tests :depends-on (#:clamber #:fiveam) :components ((:file "tests")) :perform (asdf:test-op (o s) (uiop:symbol-call :clamber/tests :run-tests)))tests.lispfile is in the repository withclamber. To run the tests issue in theREPL:(asdf:test-system 'clamber/tests)
- Prototype data persistence
To make our prototype complete we need to store our database. We will use for it a directory returned by
uiop:xdg-data-home. To serialize a hash-tablecl-storewill be used.(defparameter *database-file* (uiop:xdg-data-home "clamber" "books.db")) (defun restore-db () "Restore a database from the file." (when (probe-file *database-file*) (setf *all-books* (cl-store:restore *database-file*)))) (defun store-db () "Store a database in the file." (ensure-directories-exist *database-file*) (cl-store:store *all-books* *database-file*)) (defmethod insert-book :around ((designator symbol) &rest args &key &allow-other-keys) (declare (ignore designator args)) (prog2 (restore-db) (call-next-method) (store-db))) (defmethod delete-book :around ((designator symbol)) (declare (ignore designator)) (prog2 (restore-db) (call-next-method) (store-db))) (defmethod find-books :around (&rest args &key &allow-other-keys) (declare (ignore args)) (restore-db) (call-next-method))We read and write database during each operation (not very efficient, but it is just a prototype).
find-booksdoesn't need to store the database, because it doesn't modify it.Since our database isn't only in-memory object anymore, some additional changes to tests seem appropriate. We don't want to modify user's database:
(defparameter *test-db-file* (uiop:xdg-data-home "clamber" "test-books.db")) (defun run-tests () (let ((clamber::*database-file* *test-db-file*)) (5am:run! 'clamber)))Right now we have a "working" prototype, what we need is the user interface.
3.7 Creating standalone executable
There are various solutions which enable creation of standalone
binaries. The most appealing to me is Clon: the Command-Line Options
Nuker, which has a very complete documentation (end-user manual, user
manual and reference manual) , well thought API and works on a wide
range of implementations. Additionally, it is easy to use and covers
various corner-cases in a very elegant manner.
Our initial CLI (Command Line Interface) will be quite modest:
% clamber --help % clamber add-book foo \ --tags a,b,c \ --shelf "Favourites" \ --meta author "Bar" title "Quux" % clamber del-book bah % clamber list-books % clamber list-books --help % clamber list-books --shelf=bah --tags=drama,psycho % clamber show-book bah
3.7.1 Basic CLI interface
To make our interface happen we have to define application
synopsis. clon provides defsynopsis macro for that purpose:
(defsynopsis (:postfix "cmd [OPTIONS]")
(text :contents
"Available commands: add-book, del-book, list-books, show-book.
Each command has it's own `--help' option.")
(flag :short-name "h" :long-name "help"
:description "Print this help and exit.")
(flag :short-name "g" :long-name "gui"
:description "Use graphical user interface."))
These are all top-level flags handling main options (help and
graphical mode switch). As we can see it is declarative, allowing
short and long option names. Except flag other possible option types
are possible (user may even add his own kind of option).
clon allows having multiple command line option processing contexts,
what simplifies our task – we can provide different synopsis for each
command with its own help. First though we will define a skeleton of
our main function:
(defun main ()
"Entry point for our standalone application."
;; create default context
(make-context)
(cond
;; if user asks for help or invokes application without parameters
;; print help and quit
((or (getopt :short-name "h")
(not (cmdline-p)))
(help)
(exit))
;; running in graphical mode doesn't require processing any
;; further options
((getopt :short-name "g")
(print "Running in graphical mode!")
(exit)))
(alexandria:switch ((first (remainder)) :test 'equalp)
("add-book" (print "add-book called!"))
("del-book" (print "del-book called!"))
("list-books" (print "list-books called!"))
("show-book" (print "show-book called!")))
(exit))
(defun dump-clamber (&optional (path "clamber"))
(dump path main))
In our main we look for the top-level options first. After that we
verify which command is called. For now our action is just a stub
which prints the command name. We will expand it in the next
step. Function dump-clamber is provided to simplify executable
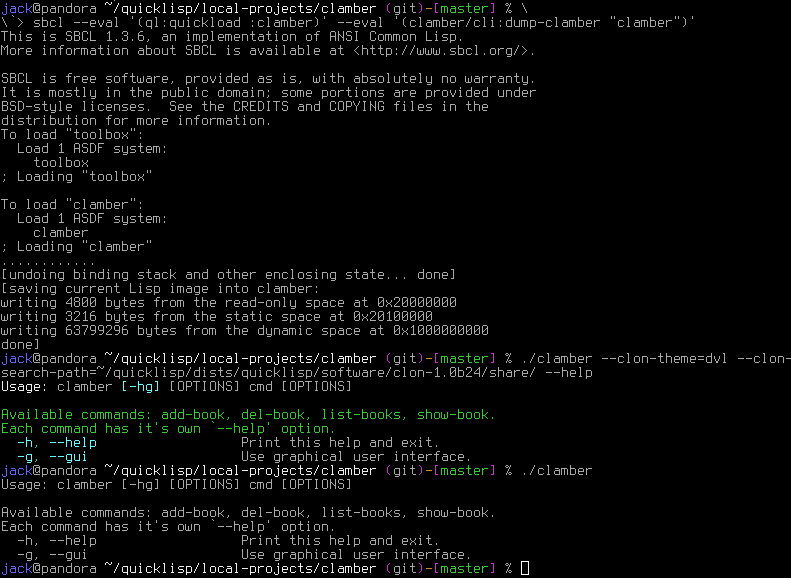
creation. To dump the executable it is enough to use this snippet:
sbcl --eval '(ql:quickload :clamber)' --eval '(clamber/cli:dump-clamber "clamber")' ./clamber --help
3.7.2 Implementing commands
Each command has to have its own synopsis. Books have unique
identifiers (designators) – we force this option to be a symbol. All
applications parameters following the options are treated as
metadata. add-book has the following synopsis:
(defparameter +add-book-synopsis+
(defsynopsis (:make-default nil :postfix "cmd [OPTIONS] [META]")
(text :contents "Add a new book to the database.")
(flag :short-name "h" :long-name "help"
:description "Print this help and exit.")
(lispobj :short-name "d" :long-name "ident"
:description "Book designator (unique)."
:typespec 'symbol)
(stropt :short-name "s" :long-name "shelf"
:description "Book shelf.")
;; comma-separated (no spaces)
(stropt :short-name "t" :long-name "tags"
:description "Book tags."))
"The synopsis for the add-book command.")
We don't want duplicated options, so we filter them out in the
add-book-main function, which is called in main instead of
printing the message. Command entry point is implemented as follows:
(defun add-book-main (cmdline)
"Entry point for `add-book' command."
(make-context :cmdline cmdline
:synopsis +add-book-synopsis+)
(when (or (getopt :short-name "h")
(not (cmdline-p)))
(help)
(exit))
(let ((ident (getopt :short-name "d"))
(shelf (getopt :short-name "s"))
(tags (getopt :short-name "t")))
(when (or (getopt :short-name "d")
(getopt :short-name "s")
(getopt :short-name "t"))
(print "add-book: Junk on the command-line.")
(exit 1))
(clamber:insert-book ident
:shelf shelf
:tags (split-sequence #\, tags)
:meta (remainder))))
To make book listing more readable we define print-object method for
books in clamber.lisp. Moreover, we tune find-books method to not
rely on the fact whenever argument was supplied or not, but rather on
its value (NIL vs. non-NIL).
(defmethod print-object ((object book) stream)
(if (not *print-escape*)
(format stream "~10s [~10s] ~s -- ~s"
(book-designator object)
(book-shelf object)
(book-tags object)
(book-information object))
(call-next-method)))
list-books command is very similar, but instead of calling
insert-book it prints all books found with clamber:find-books called
with provided arguments. Also we don't print help if called without
any options.
(defparameter +list-books-synopsis+
(defsynopsis (:make-default nil :postfix "[META]")
(text :contents "List books in the database.")
(flag :short-name "h" :long-name "help"
:description "Print this help and exit.")
(lispobj :short-name "d" :long-name "ident"
:description "Book designator (unique)."
:typespec 'symbol)
(stropt :short-name "s" :long-name "shelf"
:description "Book shelf.")
;; comma-separated (no spaces)
(stropt :short-name "t" :long-name "tags"
:description "Book tags."))
"The synopsis for the list-books command.")
(defun list-books-main (cmdline)
"Entry point for `list-books' command."
(make-context :cmdline cmdline
:synopsis +list-books-synopsis+)
(when (getopt :short-name "h")
(help)
(exit))
(let ((ident (getopt :short-name "d"))
(shelf (getopt :short-name "s"))
(tags (getopt :short-name "t")))
(when (or (getopt :short-name "d")
(getopt :short-name "s")
(getopt :short-name "t"))
(print "add-book: Junk on the command-line.")
(exit 1))
(map () (lambda (book)
(format t "~a~%" book))
(clamber:find-books :book-designator ident
:shelf shelf
:tags tags))))
Last command we are going to implement is the simplest one –
del-book:
(defparameter +del-book-synopsis+
(defsynopsis (:make-default nil)
(text :contents "Delete a book in the database.")
(flag :short-name "h" :long-name "help"
:description "Print this help and exit.")
(lispobj :short-name "d" :long-name "ident"
:description "Book designator (unique)."
:typespec 'symbol))
"The synopsis for the del-book command.")
(defun delete-book-main (cmdline)
"Entry point for `list-books' command."
(make-context :cmdline cmdline
:synopsis +del-book-synopsis+)
(when (or (getopt :short-name "h")
(not (cmdline-p)))
(help)
(exit))
(clamber:delete-book (getopt :short-name "d")))
Of course this CLI prototype needs to be improved. For instance, it doesn't handle any errors – for if we try to add a book with already existing designator. Moreover, for testing purposes it would be nice to be able to provide database file top-level argument for testing purposes.
4 Case against implicit dependencies
Sometimes implementations provide functionality which may be expected
to be present during run-time under certain conditions. For instance
when we use ASDF to load a system, we probably have UIOP available
in the image (because to load the system, we need ASDF which depends
on UIOP at its own run-time).
It is important to remember that we can't mix two very different
moments – the build time and the run-time. This difference may not be
very obvious for the Common Lisp programmer because it is common
practice to save the lisp image with the system, which was loaded with
help of the build system (hence the build system is present in the
image), or they load fasl files with the build system in
question. The fact that we have only one widely adopted building
facility, and that it is often preloaded, makes it even less possible
to encounter any problems.
There are two main arguments against implicit dependencies. The first
one is the separation of the build tool from the application. It is
hardly justifiable to include autotools
and make in your binary after building the
system. They may have exploitable bugs, increase the application size
or are simply unnecessary (unless you really depend on make at
run-time).
Assuming you rely on implicit dependencies, and given that you produce
a standalone application (or you cross-compile it), either your build
system will inject such dependency for you (what you may not
necessarily want), or your application will miss an important
component which it relies upon (for instance UIOP 2) and will
effectively crash.
The second argument has more to do with the declarative system definitions. If your application depends on something, you should list it, because it is a dependency. So if we switch the build system and it may read our declarative system definitions, or we have an older version of the build system which doesn't imply the dependency, then we can't load the system. It's not the build system problem, but our broken system definition.
Having that in mind, I sharply advocate listing all dependencies in
system definition, despite meretricious voices saying it's rudimentary
or harmful to put them there. We will take UIOP as an example. We
have two possible options:
(defsystem #:system-one (depend-on ((:require #:uiop)))) (defsystem #:system-two (depend-on (#:uiop))
system-one's dependency is resolved as follows:
- If the system
uiopis already present in the image, do nothing3, - If the system
uiopmay be acquired as a module, require it, - If the system
uiopmay be loaded by a build system, load it, - Otherwise signal a
missing-componentcondition.
This behavior is an elegant substitute for the implicit dependency,
which relies on the UIOP version bundled with the Common Lisp
implementation.
The system-two system dependency is handled in a slightly different
manner:
- If the system
uiopmay be loaded from the disk and version in the image isn't up-to-date, load the system from there, - If the image has a preloaded version of the system, do nothing,
- Otherwise signal a
missing-componentcondition.
Both definitions are strictly declarative and any build system which
"knows" the ASD file format will know your preferences disregarding
if it has UIOP bundled or not. If it can't handle it correctly, then
it is a bug of the build system, not your application.
UIOP here is only one example. I urge you to declare any
dependencies of your system. You may know that bordeaux-threads on
which you depend implies that Alexandria will be present in the
image, but this assumption may turn against you if it changes this
dependency in favour of something else.
I've asked one of a proponents of the implicit dependencies François-René Rideau for a comment to present the other point of view:
The dependency on ASDF is not implicit, it's explicit: you called your system file .asd.
Now, if you want to fight dependency on ASDF, be sure to also track those who put functions and variables in .asd files that they use later in the system itself. Especially version numbers.
Trying to enforce technically unenforceable constraints through shaming isn't going to fly. If you want to promote separation of software from build system, promote the use of Bazel or some other build system incompatible with ASDF.
Footnotes:
Since we won't use any unique ECL features we suggest using
SBCL here (it is faster and better supported by 3rd-party
libraries). Using ECL shouldn't introduce any problems though.
UIOP doesn't depend on ASDF and it may be loaded with
older versions of this widely adopted build system, or directly from
the file. Quicklisp ships UIOP this way to assure compatibility with
implementations which don't include new ASDF.
This is broken in ASDF as of version 3.1.7 – ASDF will load
the system from the disk if it is possible. It will hopefully be fixed
in version 3.1.8.